一、背景与需求
为什么需要LlamaIndex?
传统大语言模型(如GPT)存在两大局限:
知识时效性:模型训练数据截止于特定时间点,无法回答实时或私有数据问题;
上下文限制:模型输入长度有限,难以直接处理长文本或海量数据。 LlamaIndex应运而生,成为连接大模型与外部数据的“桥梁”,通过检索增强生成(RAG)技术,让模型动态获取外部知识并生成更准确的回答。
二、发展历程
起源:Meta推出LLaMA开源大模型后,开发者社区逐步构建配套工具链,LlamaIndex作为其生态中的重要数据框架诞生;
定位演变:从早期单纯的数据索引工具,发展为覆盖数据连接、结构化存储、智能查询的完整RAG解决方案。
三、核心原理
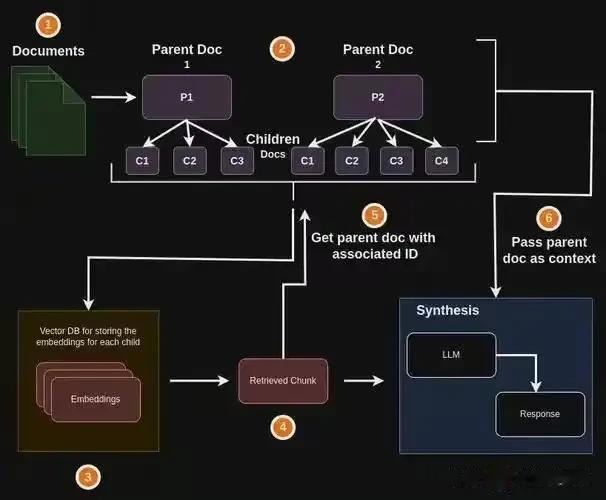
LlamaIndex的工作流程分为三个阶段:
数据连接:支持从PDF、API、数据库等多源异构数据中提取信息(如企业文档、行业报告);
索引构建:将原始数据转换为高效检索的中间格式(如向量索引、树状索引);
查询接口:用户提问时,通过语义搜索匹配索引中的相关内容,注入到大模型生成答案。
四、核心技术
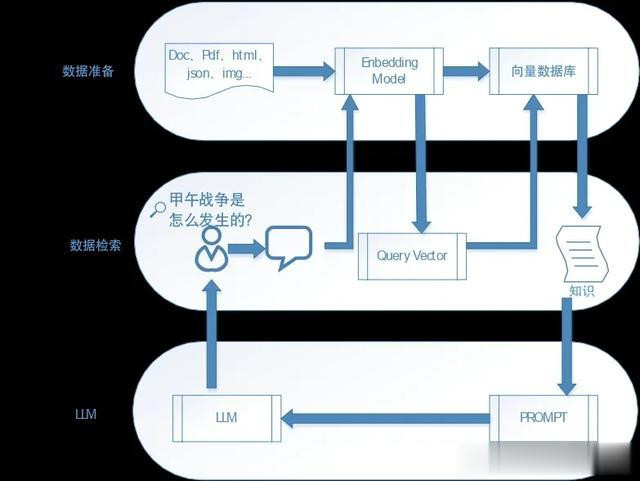
数据连接器(Connectors) 支持20+格式接入,如CSV、Notion、Slack,自动化处理数据清洗与结构化。
索引结构优化向量索引:通过文本向量化实现语义搜索;树状索引:分层存储数据,提升复杂问题的推理效率。
查询引擎(Query Engine) 结合自然语言理解与索引检索,支持多轮对话、数据过滤等高级功能。
RAG模式 动态将外部知识注入大模型上下文,解决“幻觉”问题,提升生成可靠性。
五、本地部署与API集成
本地部署步骤(简化版)
安装Python库:pip install llama-index
from llama_index import SimpleDirectoryReader documents = SimpleDirectoryReader("data").load_data
构建索引并查询:
index = VectorStoreIndex.from_documents(documents) query_engine = index.as_query_engine print(query_engine.query("文档中提到的核心技术是什么?"))
API集成场景
企业知识库:将内部Wiki数据接入LlamaIndex,实现员工自助问答;
客服系统:结合用户工单历史,生成个性化回复。
六、典型案例:企业文档智能问答系统
场景:某公司有大量产品手册和客户案例,希望快速检索信息辅助销售。
实现步骤:
索引构建:使用GPTVectorStoreIndex生成向量索引;
查询优化:设置相似度阈值过滤低质量匹配;
部署应用:通过FastAPI封装接口,集成到企业微信机器人。
效果:
销售提问“XX产品的兼容性如何?”,系统自动检索手册内容生成摘要;
响应时间从人工查找的30分钟缩短至3秒,准确率提升40%。